ElasticSearch 学习
什么是 ElasticSearch?
参考资料 ElasticSearch 官方文档
Elasticsearch 是一个分布式的免费开源 全文搜索引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。
Elasticsearch 使用 Java 语言开发,它是基于开源库 Lucene 的搜索引擎框架,它提供了分布式的 全文检索 功能,提供了一个统一的基于 RESTful 风格的 WEB 接口,官方客户端也对多种语言都提供了相应的 API。
Lucene: Lucene 就是一个由 Apache 维护的搜索库
这里的全文检索就是将一段词语进行分词,并且将分出的单个词语统一的放到一个分词库中,在搜索时,根据关键字去分词库中检索,找到匹配的内容。( 倒排索引)
而采用 RESTful 风格的 WEB 接口使得操作 ES 很简单,只需要发送一个 HTTP 请求, 并且根据请求方式的不同,携带参数的不同,执行相应的功能。
ES 和 Solr
另一个查询引擎 Solr
Solr 在查询不会变化的数据时,速度相对 ES 更快一些。但是数据如果是实时改变的,Solr的查询速度会降低很多,而 ES 的查询的效率基本没有变化。
Solr 搭建基于需要依赖 Zookeeper 来帮助管理。ES 本身就支持集群的搭建,不需要第三方的介入。
传统的搜索
而传统的数据库如果要搜索关键字采用的是模糊查询
SELECT `column` FROM `table` WHERE `field` like '%keyword%';
但是由于索引的最左匹配原则,所以会使这一块无法使用索引了
注意:也不是没法优化,网上看到一个做法就是翻转要查询的关键字,例如 “张三” 变成 “三张” 这样就可以使用右模糊查询代替左模糊查询,但是这样依旧只适合单边的查询,即 张% 或者 三% 这样的,要左右两边都使用模糊查询还是无法使用索引
倒排索引
参考资料 ES:倒排索引、分词详解
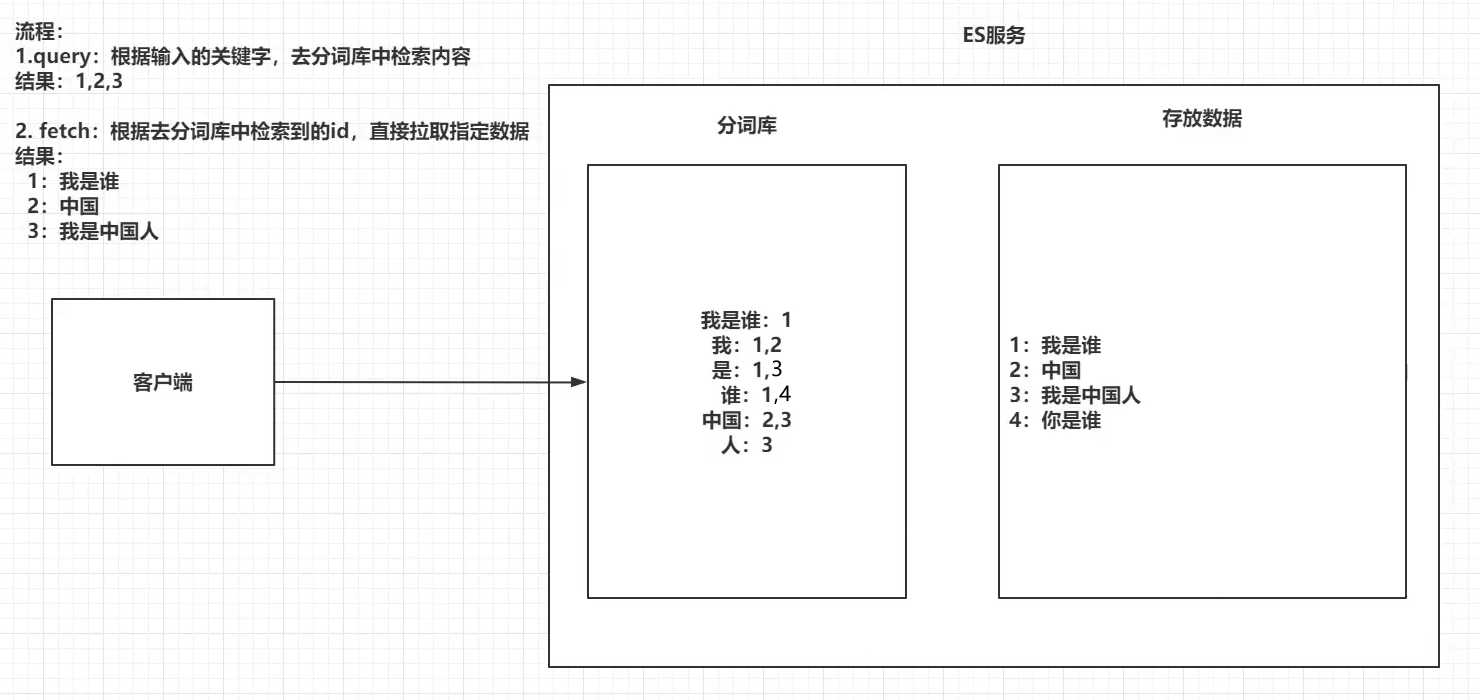
ElasticSearch 引擎把文档数据写入到倒排索引(Inverted Index)的数据结构中,倒排索引建立的是分词(Term)和文档(Document)之间的 映射关系,在倒排索引中,数据是面向词(Term)而不是面向文档的。
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表
示例:

倒排索引-查询过程:
查询包含 “搜索引擎” 的文档
- 通过倒排索引获得 “搜索引擎” 对应的文档 id 列表,有1,3
- 通过正排索引查询1和3的完整内容
- 返回最终结果
倒排索引-组成
单词词典(Term Dictionary) 倒排列表(Posting List)
配置环境
安装 ES
注意!!不要直接照搬,ES 和 Spring 有版本兼容的问题,不清楚使用什么版本参考 这个网站
也要注意 kibana 版本的选择
使用 docker-compose 进行配置,这里使用这个 DaoCloud Hub 镜像站下载
version: "3.1"
services:
elasticsearch:
image: daocloud.io/library/elasticsearch:6.8.11
# restart: always
container_name: elasticsearch
ports:
- 9200:9200
environment:
# es 默认配置初始化和最大内存为2G,如果虚拟机给的内存不够会出现内存溢出。从而启动失败
- ES_JAVA_OPTS=-Xms64m -Xmx128m
- discovery.type=single-node
- COMPOSE_PROJECT_NAME=elasticsearch-server
networks:
- esnet
# kibana 是 ES 的图形化界面
kibana:
image: daocloud.io/library/kibana:6.8.10
# restart: always
container_name: kibana
ports:
- 5601:5601
environment:
- environment_url=http://elasticsearch:9200
networks:
- esnet
# 等待 elasticsearch 启动了再启动
depends_on:
- elasticsearch
networks:
esnet:
driver: bridge
然后启动容器:
docker-compose up -d
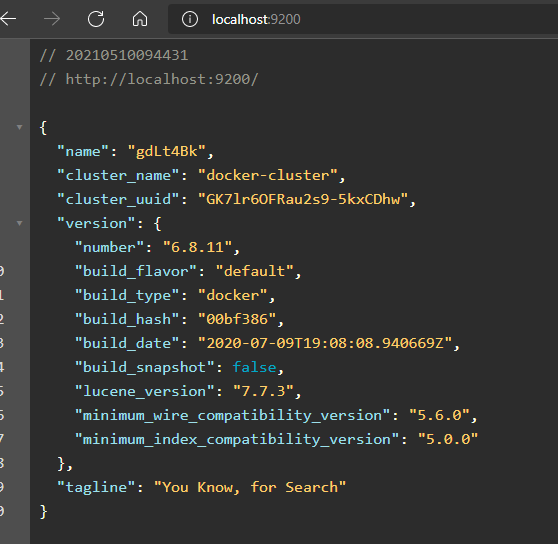
然后访问 ES,如果出现下面的这个 json 说明没有问题
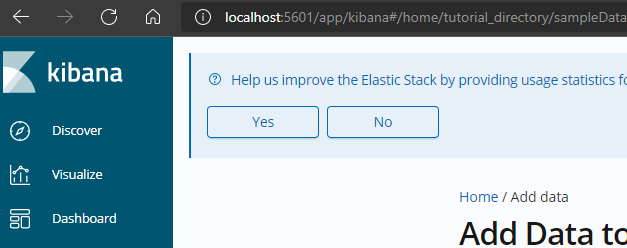
再来启动 kibana,可以看到显示的图形界面如下
补充:ElasticSearch 默认是关闭远程连接的,需要修改 ES 的配置文件
cd /usr/share/elasticsearch/config
vi elasticsearch.yml
注意:要先关掉 ElasticSearch,因为在它运行时,这个配置是只读的
# 把加在这个配置前的注释去掉
transport.host: 0.0.0.0
# 因为 ElasticSearch 这里可能是集群,所以最好写上它的名称
cluster.name: my-application
# 然后开启跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 127.0.0.1 # 这里改成当前主机的地址
系统参数配置
因为 elasticsearch 在启动的时候进行一些检查,比如最多打开的文件的个数以及虚拟内存区域数量等等,如果放开了此配置,意味着需要打开更多的文件以及虚拟内存,所以我们还需要系统调优
注意:这里是修改虚拟机的,不是修改容器的
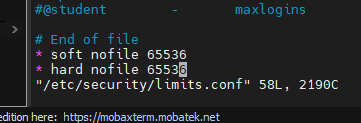
需改 vi /etc/security/limits.conf,追加内容
nofile 是单个进程允许打开的最大文件个数
- soft nofile 是软限制
- hard nofile 是硬限制
* soft nofile 65536
* hard nofile 65536
再修改 vi /etc/sysctl.conf ,追加内容,限制一个进程可以拥有的 VMA(虚拟内存区域)的数量
vm.max_map_count=65536
如果物理机内存太小了,可以再修改一下容器的 JVM 内存大小
vi /etc/elasticsearch/jvm.options
#可能在 vi /usr/share/elasticsearch/config/jvm.options
这里改成适合的大小(例如 512M)
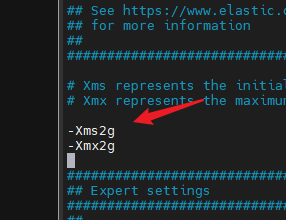
最后重启容器:
docker restart elasticsearch
安装 IK 分词器
IK 分词器 GitHub 项目地址 IK Analysis for Elasticsearch
ElasticSearch 自带的分词器对中文的分词不是很友好,所以一般需要额外安装一个中文分词器
因为这个分词器和 ES 的版本是绑定的,所以需要找到对应的版本
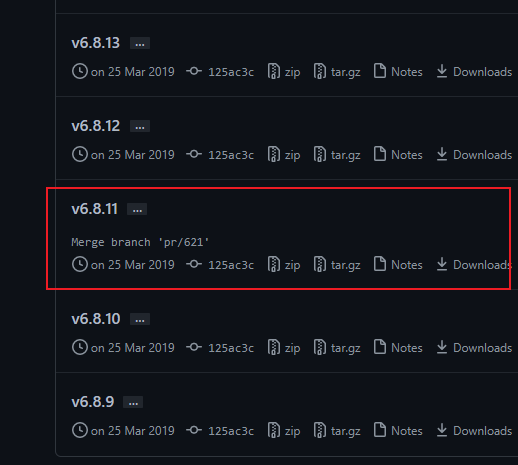
然后进入到容器去下载这个分词器
docker exec -it elasticsearch /bin/bash
# 别下载错了,下面两个是源码...
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.11/elasticsearch-analysis-ik-6.8.11.zip
不过因为魔法长城的原因,所以最好是主机下载好再拖进去
docker cp elasticsearch-analysis-ik-6.8.11.zip elasticsearch:/root
docker exec -it elasticsearch /bin/bash
elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-6.8.11.zip
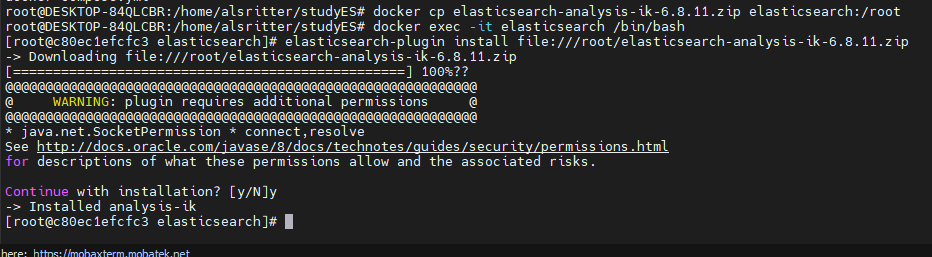
安装好后输入 elasticsearch-plugin 检查是否安装

最后重启一下 ES
docker restart elasticsearch
然后到 kibana 里面测试使用
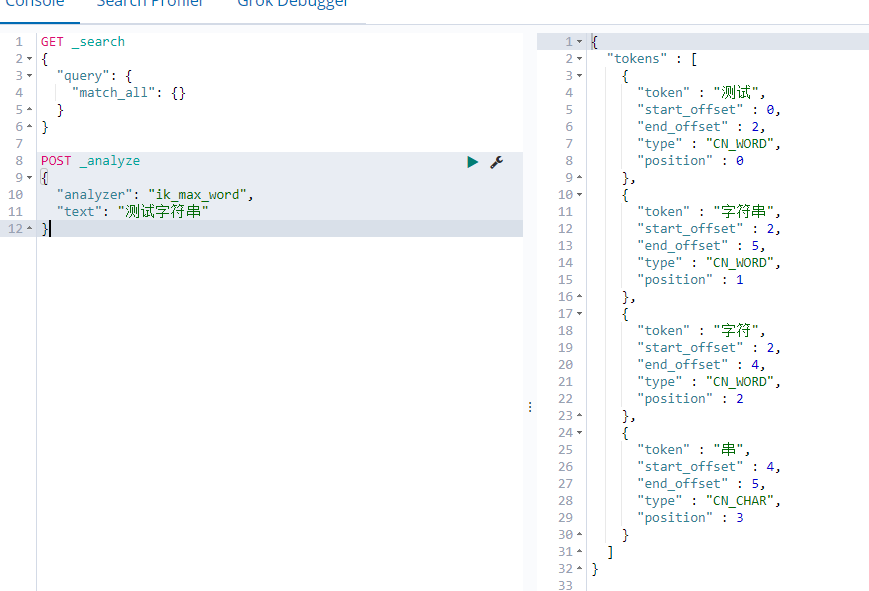
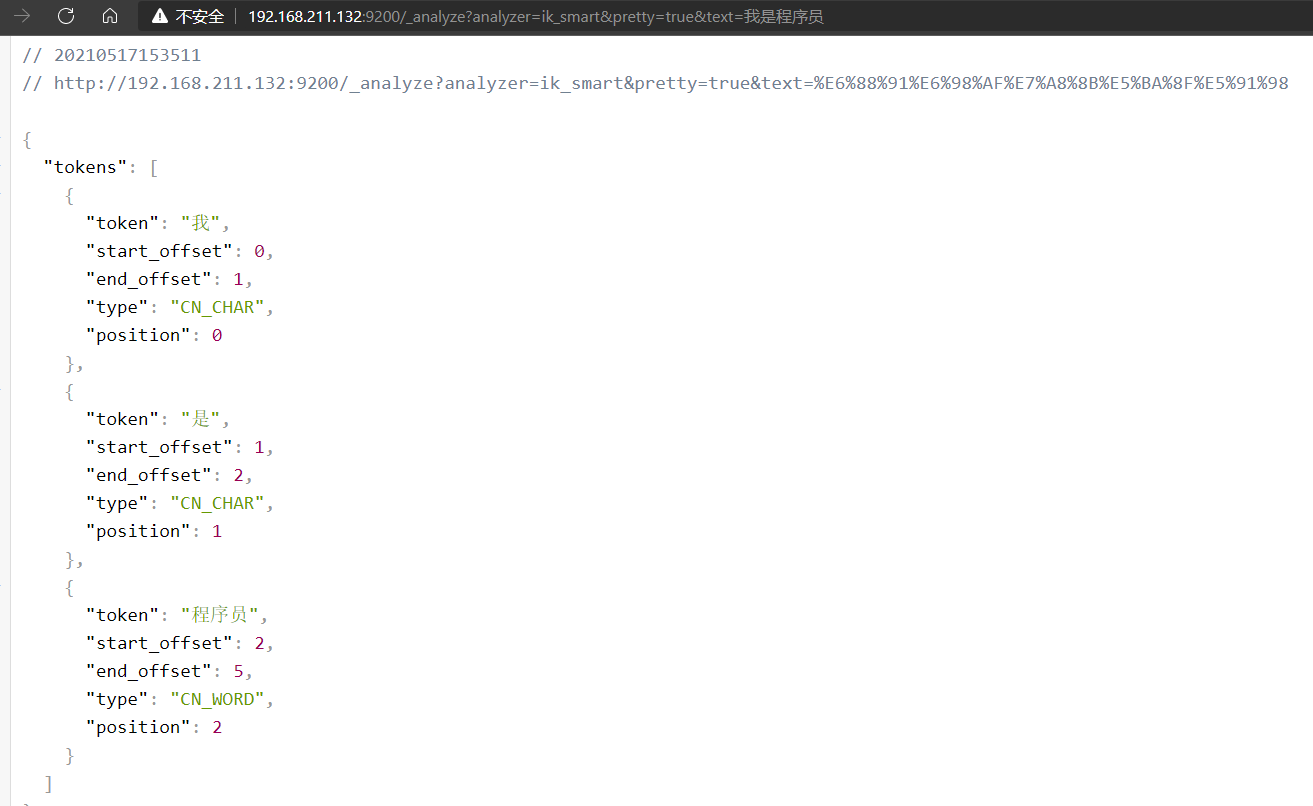
也可以使用 URL 测试
http://192.168.211.132:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员
自定义分词
修改 IKAnalyzer.cfg.xml 配置文件,添加自定义分词文件
添加停用词汇
修改 IKAnalyzer.cfg.xml 配置文件,添加停用词汇文件
ES 的结构
这个 ES 的存储结构和 MySQL 这种关系型数据库的结构还是有点相似的
| Elasticsearch存储结构 | MYSQL存储结构 |
|---|---|
| index(索引) | 表 |
| 文档 | 行,一行数据 |
| Field(字段) | 表字段 |
| mapping (映射) | 表结构定义 |
索引 index 对应库
在 7.x 之后对应表的概念
1 ES 的服务中可以创建多个索引 2 每个索引默认分成 5片存储 3 每一个至少有一个备份分片 4 备份分片正常不会帮助检索数据,除非 ES 的检索压力很大的情况发送 5 如果只有一台 ES,是不会有备份分片的,只有搭建集群才会产生 6 备份的分片必须放在不同的服务器中(上面那个原因)

索引分片是什么?
分片是 Elasticsearch 在集群中分发数据的关键。
把分片想象成数据的容器。文档存储在分片中,然后分片分配到集群中的节点上。当集群扩容或缩小,Elasticsearch 将会自动在节点间迁移分片,以使集群保持平衡。
一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分。
这类似于 MySql 的分库分表,只不过 Mysql 分库分表需要借助第三方组件而 ES 内部自身实现了此功能。
分片可以是主分片(primary shard)或者是复制分片(replica shard)。
在集群中唯一一个空节点上创建一个叫做 blogs 的索引。默认情况下,一个索引被分配 5 个主分片,下面只分配 3 个主分片和一个复制分片(每个主分片都有一个复制分片):
curl -H "Content-Type: application/json" -XPUT localhost:9200/blogs -d '
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}'
在一个多分片的索引中写入数据时,通过路由来确定具体写入哪一个分片中,大致路由过程如下:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数 。这个在 0 到 number_of_primary_shards 之间的余数,就是所寻求的文档所在分片的位置。
这解释了为什么要在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
索引中的每个文档属于一个单独的主分片,所以 主分片的数量决定了索引最多能存储多少数据(实际的数量取决于数据、硬件和应用场景)。
复制分片
复制分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的 shard 取回文档。
节点
一个 ES 节点就是一个运行的 ES 实例,可以实现数据存储并且搜索的功能。每个节点都有一个唯一的名称作为身份标识,如果没有设置名称,默认使用 UUID 作为名称。最好给每个节点都定义上有意义的名称,在集群中区分出各个节点。
一个机器可以有多个实例,所以并不能说一台机器就是一个 node,大多数情况下每个 node 运行在一个独立的环境或虚拟机上。
类型 type 对应 “table”
1 ES5.x下,一个 index 可以创建多个 type 2 ES6.x下,一个 index 只能创建一个 type 3 ES7.x下,直接舍弃了 type,没有这玩意了
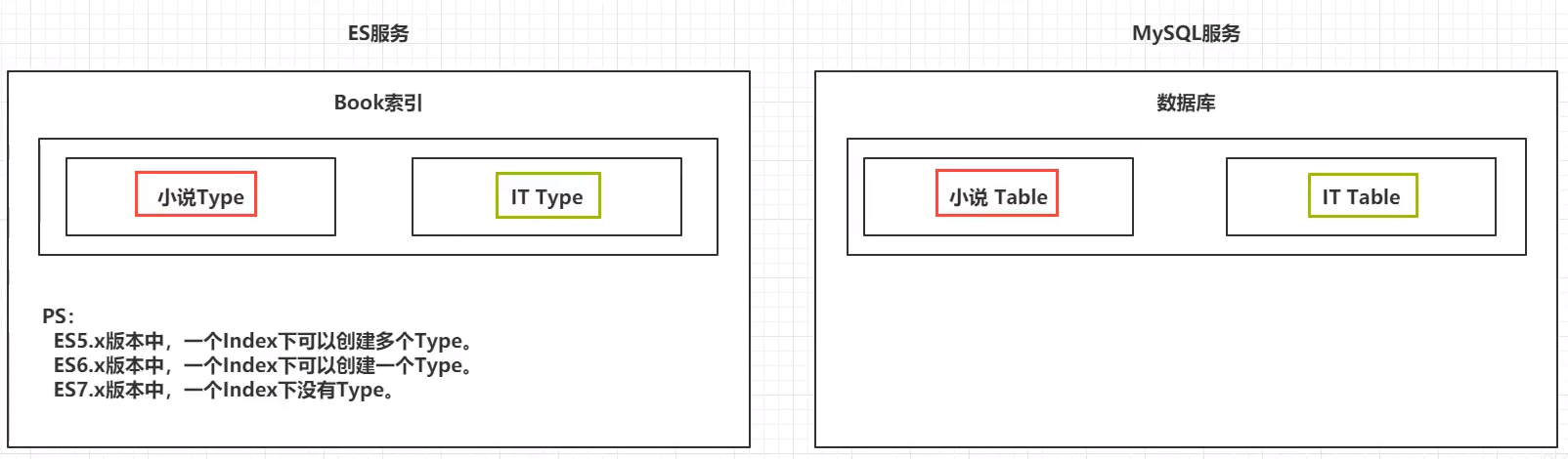
需要注意的是,从 Elasticsearch5.x 开始就提出了弱化索引类型 type 的使用,起初,我们说 “索引” 和关系数据库的 “库” 是相似的,“类型” 和 “表” 是对等的。这是一个不正确的对比,导致了不正确的假设。
在关系型数据库里,“表” 是相互独立的,一个 “表” 里的列和另外一个 “表” 的同名列没有关系,互不影响。但在类型里字段不是这样的。
举个例子,两个不同 type 下的两个 user_name,在 ES 同一个索引下其实被认为是同一个 filed,你必须在两个不同的 type 中定义相同的 filed 映射。否则,不同 type 中的相同字段名称就会在处理中出现冲突的情况,导致 Lucene 处理效率下降。
所以在 Elasticsearch7.x 就完全去除了 type。每个索引的 type 默认且只有为 _doc。
文档 doc 对应行
一个 type 下可以有多个文档 doc,这个 doc 就类似 mysql 表中的行

属性 field 对应列
一个 doc 下可以有多个属性 field,就类似于 mysql 的一列有多行数据

映射 mapping
Elasticsearch 的 mapping (映射)类似 mysql 中的表结构定义,每个索引都有一个映射规则,我们可以通过定义索引的映射规则,提前定义好文档的 json 结构和字段类型,如果没有定义索引的映射规则,Elasticsearch 会在写入数据的时候,根据我们写入的数据字段推测出对应的字段类型,相当于自动定义索引的映射规则。
提示:虽然 Elasticsearch 的自动映射功能很方便,但是实际业务中,对于关键的字段类型,通常预先定义好,避免 Elasticsearch 自动生成的字段类型不是你想要的类型,例如: ES 默认将字符串类型数据自动定义为 text 类型,但是关于手机号,我们希望是 keyword 类型,这个时候就需要通过 mapping 预先定义号对应的字段类型了。